Twitter Hashtag Usage Visualization
This program visualizes Twitter hashtag usage over time as a collection of circles, each corresponding to a hashtag. The size of the circles are proportional to the usage frequency of the hashtag at a point in time.
This program is written in Lua and uses the LOVE framework for graphics and user input. A python script was used to collect and format Twitter data. The Box2d physics engine was used to handle collisions between circles.
Video
The following video shows the program in action. The dataset in this video consists of 120,000 tweets spanning a 6 hour period from 3pm to 9pm (PST) on October 15th, 2013.
Data Collection
Data is collected by using the Twitter Firehose which is offered by Twitter's Streaming API. Only tweets in the English language which contained at least one hashtag mention are collected. Relevant data is then serialized into chunks of data in the form of Lua tables. Data chunks have a naming convention of:
data-000.lua
data-001.lua
data-002.lua
data-003.lua
.
.
.
Click for an example of a small serialized data chunk consisting of 9 tweets
The data chunks are then fed into the program where the user is able to set the speed of playback.
Data Analysis
A useful feature of this program is the ability for the user to select a hashtag bubble to view the defining words of a hashtag. Defining words are selected by using the term frequency-inverse document frequency (tf-idf) statistic method.
The following image displays a tf-idf visualization for the hashtag "#ENGvPOL". The size of the hashtag bubble is proportional to the relevance of the tf-idf statistic.
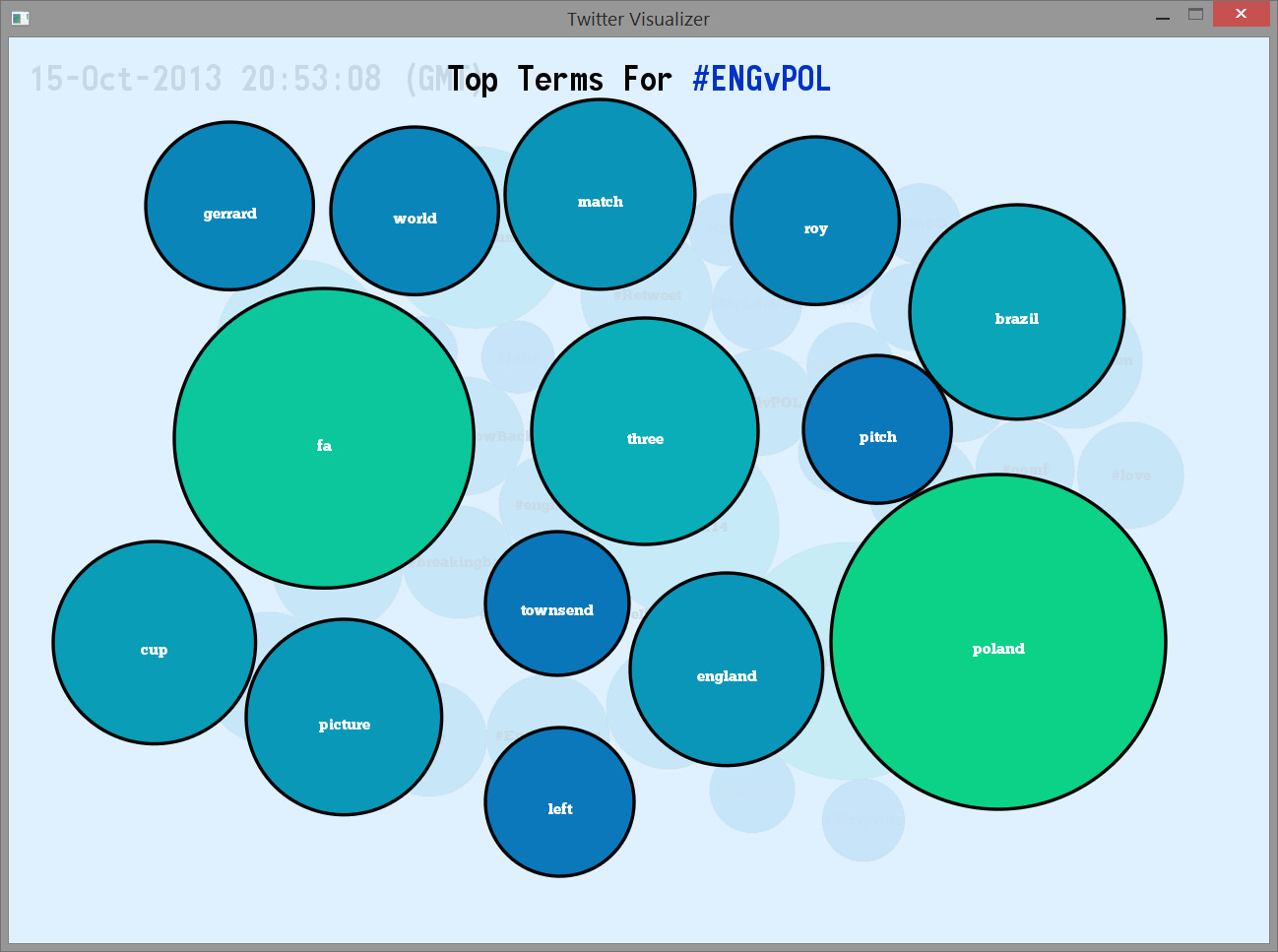
The following sample raw tf-idf data is from a dataset collected on December 5th, 2013.
Click for a sample of raw tf-idf dataA notable event on this day was the death of Nelson Mandela. The following table shows the defining terms along with their tf-idf scores for the hashtag #RIPNelsonMandela.
| Term | TF-IDF Score |
|---|---|
|
nelson mandela inspiration man world hero rip inspirational lost impossible legend peace jackwilshere triumph lukebrooks absence true forgotten such courage seems was always great zendaya |
1.6539901565698 1.6384451363013 1.0068699494976 0.90116939120047 0.83510916049347 0.64903928290753 0.61338731204298 0.55197304242504 0.54569420235328 0.51504720578213 0.50972674646087 0.50338493483912 0.49945073541737 0.49856453112542 0.49576923098456 0.48915765317966 0.48799009177079 0.48700501122069 0.48232219138257 0.47421325948613 0.44086341636686 0.43949814863293 0.43601620113473 0.4308400206291 0.42257837370852 |
Downloads
Windows 32-bitOS X
Linux - Linux users will need to install the LOVE package (http://love2d.org)
Source: https://github.com/rlguy/twitter_hashtag_visualizer